Disséquer la variabilité génétique dans le virus de la COVID-19
Le travail de Dre Hussin et de son groupe de recherche consiste à résoudre des questions biologiques à l’aide d’outils de calcul d’informatique de pointe. Ces jours-ci, l’équipe cherche des mutations dans le SARS-COV-2, le virus responsable de la maladie COVID-19.
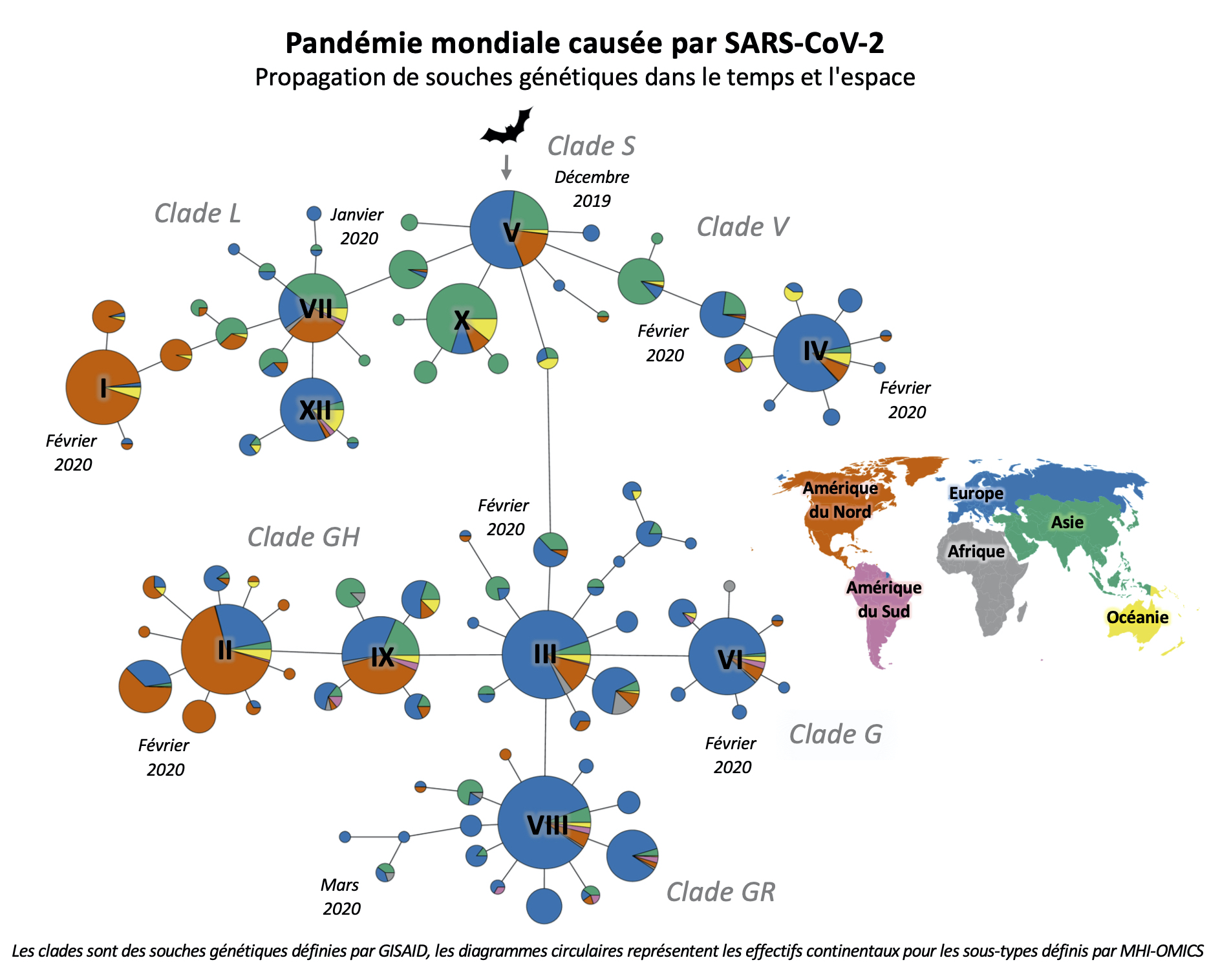
« À la base, c’était un petit projet avec mon bio-informaticien senior, raconte-t-elle. On prenait toutes les séquences qui apparaissaient de semaine en semaine et on regardait comment elles mutaient d’une génération à l’autre, selon le pays.»
« On a découvert de la variabilité », précise-t-elle. Cette variabilité est le pain quotidien de cette équipe de spécialistes en génétique des populations.

Dre Julie Hussin, Professeure adjointe, Université de Montréal Crédit photo : IVADO
Pourquoi étudier la variabilité ? La première fois que SARS-COV-2 a infecté un humain, son génome contenait une certaine séquence d’ARN (tandis que le génome humain est composé d’ADN). Lorsque le virus crée des répliques de lui-même, des erreurs aléatoires peuvent s’infiltrer dans la séquence d’ARN. Les effets de ces mutations peuvent s’avérer bénéfiques, nuisibles ou inconséquents pour le virus. Dans tous les cas, elles risquent d’engendrer de nouvelles souches. Les pressions qui varient d’un humain à l’autre ou même à l’intérieur d’un individu influencent la survie, la réplication et la transmission des différentes souches. Certaines souches pourraient donc développer des avantages spécifiques.
« Le génome du virus code spécifiquement pour des protéines qui vont permettre son entrée dans la cellule », explique Dre Hussin. L’astuce est de déterminer quelles mutations vont affecter sa capacité à accomplir cette tâche.
Alors que la situation à travers le monde s’aggravait, l’équipe de Dre Hussin commençait à comprendre l’importance de leur travail. « En tant que scientifiques […] on voulait faire quelque chose, même si on ne savait pas si ça allait marcher », dit-elle. « En parallèle, on a eu du financement, donc notre projet a pris un peu d’ampleur ! ».
Des étudiants de Julie Hussin se sont alors mis à appliquer des méthodes existantes à l’analyse de SARS-COV-2. De leurs côté, ses bio-informaticiens ont commencé à analyser les données génétiques en construisant des chaînes d’opérations. En combinant plusieurs logiciels, cette technique permet de convertir, de raffiner, puis d’analyser les données brutes.
La bio-informatique est un champ d’études encore jeune et peu connu en dehors des cercles scientifiques. Bien que pour ce projet, le groupe de Julie Hussin n’œuvre pas sur des bancs de laboratoire, leur travail est essentiel à la recherche de médicaments et de vaccins contre la COVID-19. Chaque génome de coronavirus comptant autour de 30 000 bases, Dre Hussin et ses programmeurs chevronnés ne pourraient pas analyser le niveau faramineux de variabilité et toutes les corrélations possibles sans Calcul Québec et Calcul Canada. Des calculs prenant quelques secondes avec des supercalculateurs pourraient prendre plusieurs heures avec leurs ordinateurs personnels. Ceux qui prennent des semaines prendraient des mois, voire des années. « Sans Calcul Québec, on ne pourrait pas faire cette recherche à temps », insiste-t-elle.
« On est encore dans la collecte et l’exploration de données », précise-elle. Jusqu’à présent, son équipe ne peut qu’étudier les séquences génomiques d’échantillons viraux obtenues des personnes infectées, car il manque encore leurs données complémentaires.
À cet effet, des consortiums de scientifiques tentent de rassembler toutes les données disponibles sur les personnes qui ont reçu un résultat positif pour la COVID-19 au Québec, au Canada et à travers le monde. Ils cherchent à connaître leurs antécédents médicaux, si elles ont dû être hospitalisées, si elles ont eu des complications et, bien sûr, si elles ont survécu ou non.
Les ressources de Calcul Québec et de Calcul Canada, combinées avec les technologies d’intelligence artificielle en développement en collaboration avec Mila, financé par l’Institut de valorisation des données (IVADO), permettent à son équipe de se préparer à l’arrivée des données humaines. Aussitôt qu’ils auront ces données, l’objectif sera d’identifier un sous-ensemble d’individus affectés par une souche de SARS-COV-2 qui répondront à un traitement efficace.
« Évidemment, dit-elle, on espère trouver un traitement qui pourrait s’appliquer au plus grand nombre de personnes, mais c’est rarement le cas avec les maladies complexes », son équipe continue d’affiner ses outils de travail en prévision de l’éventuelle vague de données humaines.
« Nous serons prêts à disséquer tous les différents niveaux de variabilité », conclut-elle.
Crédit photo : Julie Hussin
